2025年4月集成电路学院缪向水、王兴晟教授团队在电路领域主要期刊IEEE Transactions on Very Large Scale Integration (VLSI) Systems上发表了题为“ISARA: An Island-Style Systolic Array Reconfigurable Accelerator Based on Memristors for Deep Neural Networks” (应用于深度神经网络的基于忆阻器的岛式脉动阵列可重构加速器),该论文提出了一种基于忆阻器的岛式脉动阵列可重构加速器(ISARA),以满足边缘人工智能(AI)的计算加速需求,推动了边缘 AI 计算硬件的发展。
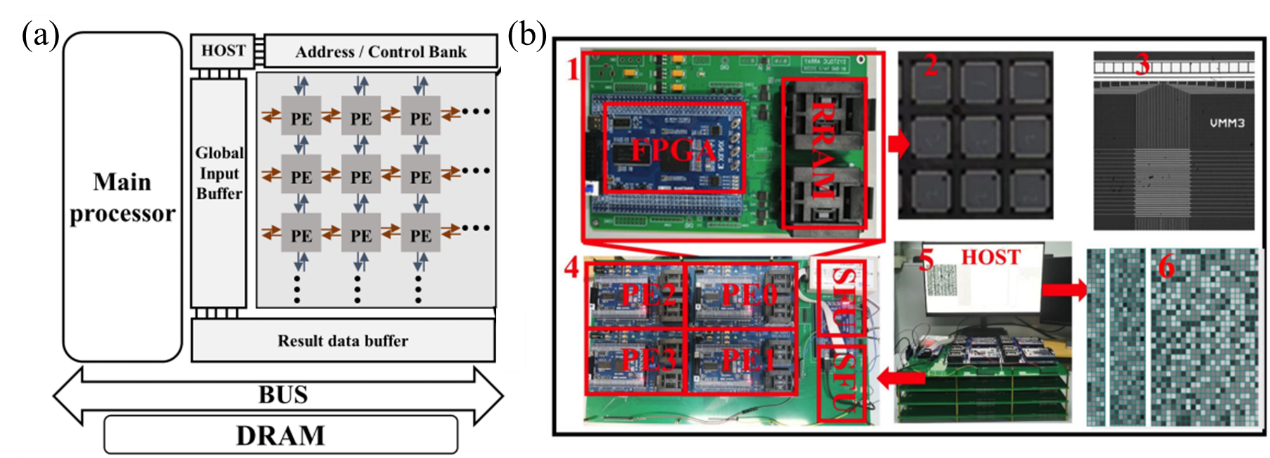
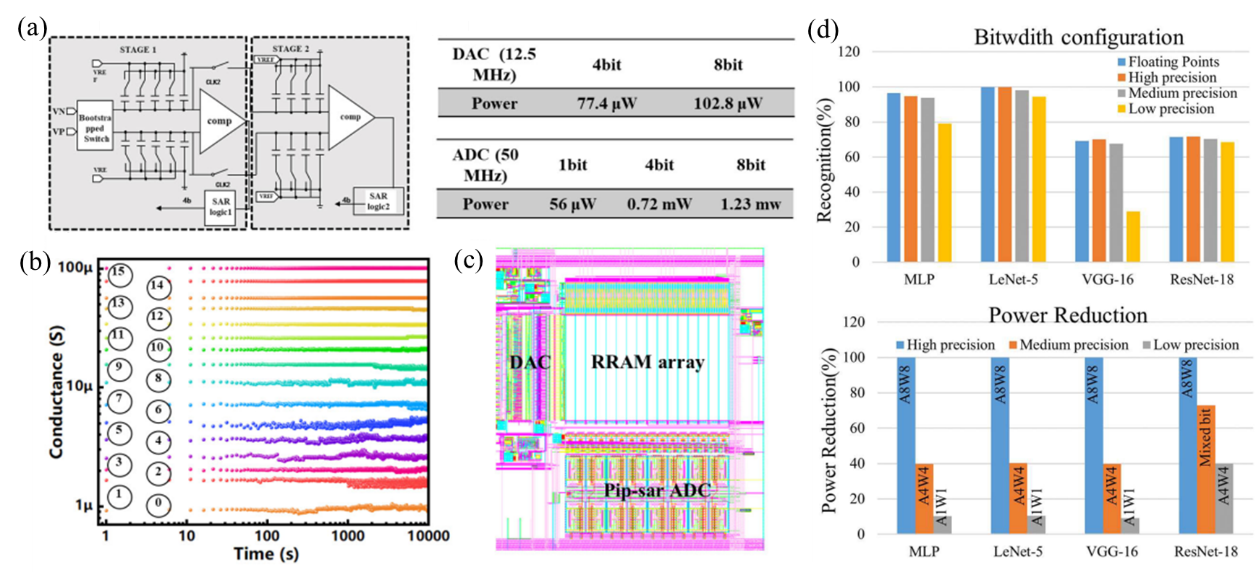
传统冯・诺依曼架构由于“功耗墙”与“存储墙”不适合边缘AI应用,存内计算(CIM)成为新选择,基于忆阻器的神经网络加速器受到广泛关注。但基于非易失性存储器的 DNN 存内加速器面临架构、电路和器件层面的挑战。采用岛式脉动阵列架构,以 PE 为基本单元灵活扩展,减少数据传输和延迟。设计 1/4/8 位流水线逐次逼近寄存器(PIP-SAR) ADC,根据神经网络层的位宽量化调整精度,降低功耗。利用脉动阵列计算时序,融合多个低精度忆阻器件存储 8 位权重,减少器件电导随机性非理想因素对精度的影响。
基于180nm CMOS工艺完成 PE 电路设计,验证了忆阻器芯片和硬件系统。构建基于 忆阻器芯片的电路系统,部署 CNN 算法,识别精度达 97%,与软件实现相当。与其他加速器相比,ISARA 在计算效率和吞吐量上表现出色,CIM 单元利用率高,达 99.93%(VGG-11)。处理不同神经网络时,延迟比PUMA等低200倍。位融合方法可节省 30%-60% 能耗,识别精度损失不超 3%。
ISARA 通过开发的忆阻器芯片和硬件系统得到验证,其片上网络提高了数据传输效率,降低了延迟。灵活的PE组合和神经网络层间数据调度与映射提高了计算吞吐量和硬件利用率,位融合解决了ADC功耗和精度问题,硬件测试结果验证了其可行性和可靠性。
该忆阻器存算一体芯架构在可重构性、流水线处理和调度、非理想性因素调控等方面做出了创新,为边缘智能计算提供了灵活的高算力高能效硬件基础。
论文信息:F. Yang, N. Li, L. Wang, P. Jiang, X. Miao and X. Wang, "ISARA: An Island-Style Systolic Array Reconfigurable Accelerator Based on Memristors for Deep Neural Networks," in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 33, no. 4, pp. 963-975, April 2025, doi: 10.1109/TVLSI.2024.3521394.
论文链接:https://ieeexplore.ieee.org/document/10891373



